
[Paper Review] Masked Autoencoders Are Scalable Vision Learners
Paper : https://arxiv.org/pdf/2111.06377
Github : https://github.com/facebookresearch/mae
Masked Autoencoders Are Scalable Vision Learners는 컴퓨터 비전 분야에서 자기지도 학습(Self-supervised Learning)을 위한 혁신적인 접근 방식을 제시한 논문이다. 요즘 모델들은 수많은 데이터들로 학습을 하고 있으며 Computer Vision에서는 Supervised Learning이 대부분인 반면에 NLP 분야에서는 Self-supervised Learning이 큰 성공은 이뤘다. 문장에서 단어 몇개를 가린 후 원래의 문장(가려진 단어)을 예측하는 식으로 학습이 되고 있는데 이러한 방법을 통해 1,000억 개 이상의 파라미터를 가진 모델을 일반화 할 수 있게 됐다.
이미지에 일부를 가려서 학습하는 기법은 Computer Vision에서 먼저 연구가 되었지만 NLP 보다 뒤쳐져 있다. (i) 최근까지만 해도 Convolution 기반의 네트워크가 대부분이였지만 ViT의 등장으로 NLP와 비슷한 구조로 학습이 가능해졌다. (ii) 언어와 이미지는 정보 밀도가 다르다. 이미지는 공간적인 중복이 심하며 일부분이 가려지더라도 주변 픽셀을 통해 쉽게 예측이 가능하기 때문에 수많은 픽셀을 가려 해결하도록 하였다. (iii) NLP에서 큰 성공을 거둔 BERT 모델에서는 Decoder 부분이 크게 중요하지 않을 수 있지만 이미지의 경우 픽셀을 복원해야하기 때문에 Decoder가 매우 중요하다는 것을 알게 되었다. 이러한 분석을 통해 일반화가 잘 되는 고용량의 모델을 만들 수 있었다.
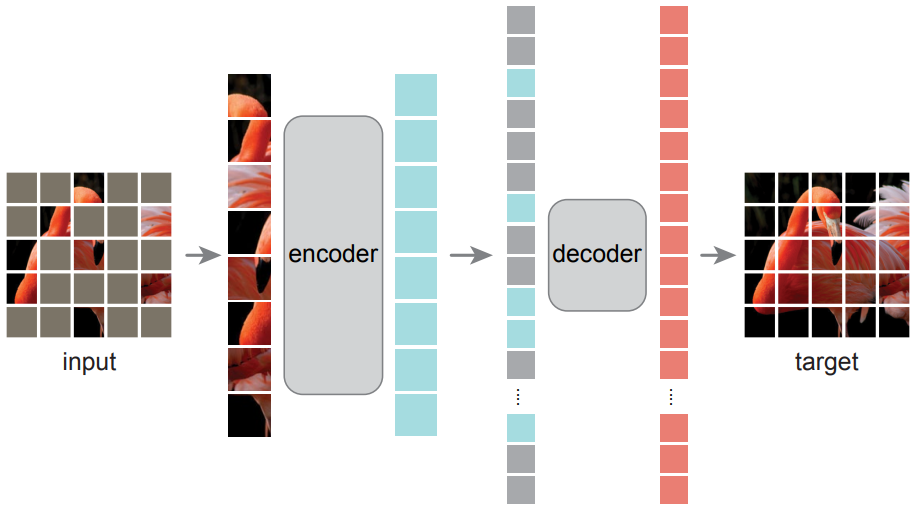
📚 사전 지식
이 논문을 효과적으로 이해하는 데 필요한 사전 지식을 정리했다.
(간단하게 설명하기 위해 생략된 부분이 많습니다. 따로 정리하게 된다면 링크 걸어두겠습니다. 🙇)
1. Self-supervised Learning (자기지도 학습)
- Self-supervised Learning은 라벨이 없는 데이터로 학습을 하며, 데이터 자체에서 학습 목표를 생성한다는 특징이 있다.
- 라벨이 존재하지 않는 원본 데이터로부터 라벨을 자동으로 생성하여 학습에 사용하며 대표적인 예로는 Self-predicting Learning, Contrastive Learning 등이 있다.

2. AutoEncoder (오토인코더)
- AutoEncoder는 Self-supervised Learning 방법 중 하나이다. (Self-predicting Learning)
- Encoder와 Decoder로 구성되며 Encoder는 데이터의 표현(representation)을 잘 압축하도록 학습하고, Decoder는 Latent Vector z로부터 이미지를 복원(Reconstructed)하는 것을 학습한다.

3. Vision Transformer
- ViT(Vision Transformer)는 자연어 처리에서 사용되는 Transformer 구조를 Vision Task에 적용한 모델이다.
- Input Image를 Patch로 분할하여 Position Embedding을 해준 후, Attention 매커니즘을 적용한다

4. BERT (Bidirectional Encoder Representations from Transformers)
- BERT는 구글에서 개발한 자연어 처리 모델이다.
- BERT는 문장 내 단어의 의미를 예측하기 위해 일부 단어를 Masking한 후 이를 복원하는 Self-supervised Learning 방식으로 학습한다.

5. Finetuning and Linear Probing
- 아래 그림처럼 Pretrained은 일반적으로 모델을 처음부터 학습시키는 것을 의미한다.

- Finetuning과 Linear Probing의 공통점은 Pretrained 모델을 사용한다는 점이고, 차이점은 Finetuning은 Pretrained된 부분도 재학습 시키지만, Linear Probing은 Pretrained된 부분은 Freeze 시키고(재학습 X) 새로 붙인 Layer만 재학습을 시킨다.


🎭 Masked AutoEncoder
Masked AutoEncoder에서 사용된 방법에 대해 하나씩 알아본다.
👻 Masking
- ViT처럼 이미지를 패치로 나눈 후에 Random Sampling을 통해 masking을 하였다.

- 높은 Masking Ratio로 중복성을 크게 제거하여 인접 패치에서 추정하는 것으로는 쉽게 해결할 수 없도록 만들었다.
- Masking Ratio가 75%일 때 Fine-tuning과 Linear probing에서 성능이 우수하다.

- Random Sampling으로 인해 Center Bias를 방지한다. (모델이 이미지 중심이 중요하다고 생각하는 것을 방지)
- Block Masking은 50%에서는 잘 작동하지만 75%부터는 성능이 저하된다.
- Grid Masking은 Block Masking보다 재구성이 더 선명하지만 Representation Quality가 낮다.
- Random Sampling Masking 방법이 MAE에 가장 적합하다.

📓 MAE encoder
- Encoder에서는 Masking 되지 않은 패치만 입력으로 사용한다.
- 모든 패치를 사용하지 않기 때문에 적은 리소스만으로 Encoder를 학습할 수 있다.

- MAE에서 중요한 부분은 Encoder는 Mask Token을 건너뛰고 Decoder에 적용하는 것이다.
- Encoder에서 Mask Token을 사용하는 경우 Linear Probing에서 약 14% 성능이 감소했다.
- 학습 시에만 Masking 되어 들어오기 때문에 실제 추론을 할 때는 차이가 존재한다.

- Encoder에서는 Mask Token을 건너뛰었을 때 학습에 소요된 시간이 줄어들었다
- Masking Ratio 75%기준으로 ViT-L에서는 2.8~3.7배, ViT-H에서는 3.5~4.1배
- 시간과 메모리 효율성 덕분에 MAE는 큰 규모의 모델을 학습하는데 유리하다.

🔓 MAE decoder
- Decoder에는 Encoder에서 나온 패치와 Mask token이 입력된다.
- Mask Token은 이미지에서 누락된 부분을 표시하는 공유된 학습 파라미터다.
- 모든 토큰에 positional embedding을 추가해 자신의 대한 정보를 갖도록 한다.
- Decoder는 Pre-train에서만 사용된다.

- 일반적인 AutoEncoder 구조와 달리 Encoder와 Decoder의 크기가 다르다. (Asymmetrical design)
- 기본 Decoder는 Encoder의 비해 Token당 연상량이 10% 미만이다.
- 이러한 비대칭적 설계를 통해 전체 Token 세트는 경량 Decoder에서만 처리되므로 pre-train 시간이 크게 단축된다.

- Linear Probing에서는 Decoder의 depth가 깊은게 성능이 우수하다.
- Finetuning에서는 Decoder의 depth가 크게 영향이 없다.
- Decoder의 width는 512일 때가 finetuning과 linear probing에서 성능이 가장 좋다.

🏗️ Reconstruction target
- Decoder의 출력은 각 패치를 나타내는 픽셀 값의 Vector다.
- Loss function은 재구성된 이미지와 원본 이미지 사이의 MSE를 계산한다.
- 여기서 BERT와 유사하게 Masking된 패치에서만 Loss 를 계산한다.

- 패치별로 정규화를 적용한 픽셀을 사용했을 경우 가장 좋은 성능을 보인다.
- PCA 방법을 사용해 이미지 패치에서 가장 중요한 특징 96개를 추출해 사용한 경우 성능이 오히려 떨어진다.
- 이는 이미지의 세밀한 특징들이 중요하다는 것을 보여준다.
- dVAE 토큰화 방법을 사용했을 때 성능이 올랐으나 이는 추가 사전학습이 필요하며 계산량이 많다. (BEiT 에서 제안된 방법)

🤖 Data Augmentation
- Crop 후에 fixed size와 rand size를 적용했을 때 모두 성능이 준수하다.
- Color jitter를 추가하면 성능이 저하된다.
- Data augmentation을 적용하지 않아도 성능이 어느정도 나온다.
- MAE에서는 Data augmentation의 역할은 주로 Random Masking에 의해 수행되기 때문에 적은 Augmentation만으로 성능이 우수하다.

🧪 실험 및 결과
- MAE는 Epoch가 늘어나도 정확도는 꾸준히 향상된다. (1600epoch 기준)
- Contrastive Learning 중 하나인 MoCo v3(ViT-L)는 300epoch에서 정확도가 포화 상태에 도달한다.
- 유의할 점은 학습시에 MAE는 epoch 당 25%의 patch만 보고 MoCo v3는 200% 이상의 패치를 본다.

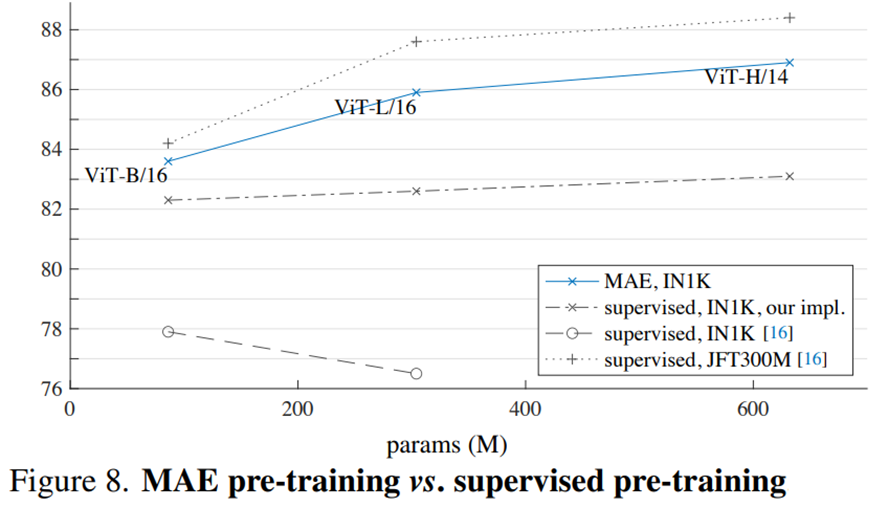
- 기존 ViT 논문에서 ViT-L은 IN1K(ImageNet-1k)에서 훈련할 때 성능이 저하된다.
- Supervised Learning은 모델이 커져도 정확도가 크게 오르지 않는 포화상태에 이른다.
- IN1K만 사용하여 MAE를 학습하는 경우 일반화를 더 잘 할 수 있으며, 모델이 커질 수록 성능이 높아진다.
- 이는 ViT를 JFT-300M으로 학습시킨 결과와 유사한 추세를 따른다.

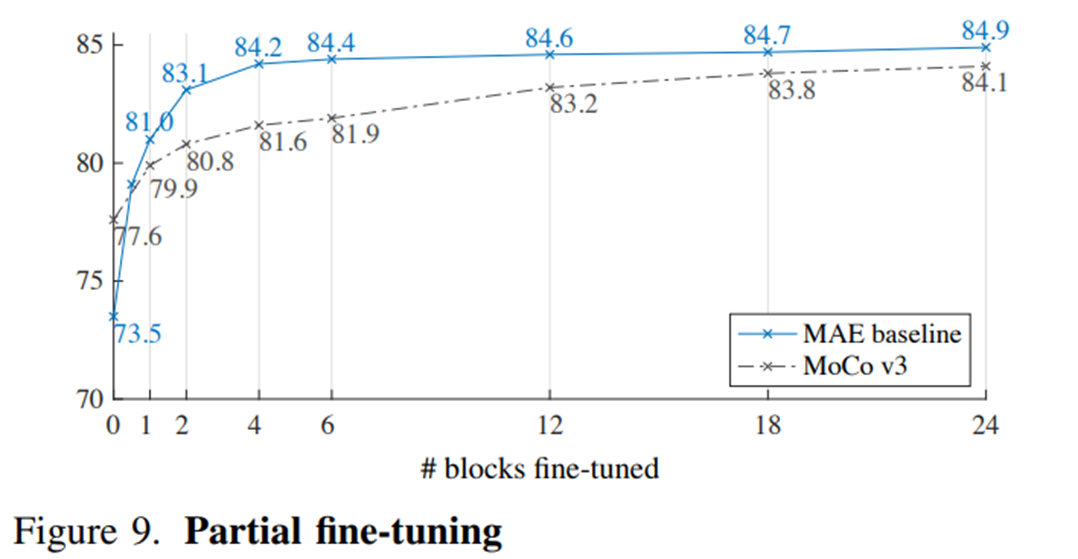
- Encoder에서 1개의 Transformer Block에 대해서 fine-tuning을 해도 성능이 크게 향상하는 것을 볼 수 있다. (73.5% -> 81.0%)
- 맨 마지막 Transformer Block의 MLP 부분만 Fine-tuning해도 성능이 크게 오른다. (73.5% -> 79.9%)
- MoCo v3 와 비교했을 때 MAE는 적은 Block의 fine-tuning만 하여도 최고 성능과 비슷한 성능을 보인다.
- MAE 방식으로 Pretrain된 Network를 Transfer Learning 하여 사용했을 때 좋은 성능을 보인다.
- iNat 데이터셋에서도 우수한 성능을 보이며, 다양한 데이터셋으로의 일반화 성능이 뛰어나다는 것을 입증한다.
- 또한, 모델이 커질수록 정확도가 크게 향상된다.

- Figure 2는 ImageNet 데이터셋의 Validation 이미지이며, Figure 3는 COCO 데이터셋의 Validation 이미지다. (ImageNet 데이터셋을 학습시킨 모델 사용)
- 아래 그림에서 볼 수 있듯이, 다른 데이터셋으로 학습을 시켜도 어느정도 일반화가 가능한 것을 나타낸다.

🏁 결론
NLP 분야에서는 self-supervised learning이 큰 성공을 이룬 것에 비해, Computer Vision에서는 여전히 Supervised Learning이 많이 쓰이고 있다. 해당 연구를 통해 Vision 분야에서도 Self-Supervised Learning이 성공할 수 있음을 보여주었으며 이미지와 언어는 다른 성격의 신호이며 이러한 차이는 신중하게 해결해야한다고 주장한다. MAE에서는 무작위로 패치를 제거하여 픽셀 단위로 복원하였으며 복잡하고 전체적인 이미지 복원이 가능하다. 이는 MAE가 의미있는 시각적 개념들을 학습했다는 것을 보여줬으며 MAE 내부에 풍부한 hidden Representation이 형성되었기 때문이라고 추정한다.