
Paper : https://arxiv.org/pdf/1706.03762
Github : https://github.com/tensorflow/tensor2tensor
2017년에 구글 브레인에서 발표한 논문이며 해당 논문에서 Transformer 구조를 처음 소개한다.
기존의 RNN 기반 모델들은 순차적 처리로 인한 병렬화의 한계와 장기의존성(long-term dependencies) 문제를 완전히 해결하지 못했으며, CNN과 RNN을 혼합한 복잡한 구조는 학습에 어려움이 있었다. 이러한 한계를 극복하기 위해 논문에서는 RNN과 CNN 없이 순수하게 Attention 방법만으로 구현된 Transformer 구조를 제안했다. 해당 구조는 WMT 2014 영어-독일어 번역 태스크에서 BLEU 점수 28.4, 영어-프랑스어 번역에서 41.8을 달성하며 SOTA를 이뤘다. 기존 모델들보다 적은 학습 시간이 필요했으며 NLP 분야에 큰 영향을 미쳤다.
현재까지도 후속 연구의 기반이 되고 있기 때문에 논문을 다시 한번 읽고 정리해 본다.

📚 사전 지식
이 논문을 효과적으로 이해하는 데 필요한 사전 지식을 정리했다.
seq2seq
seq2seq(Sequence-to-Sequence)는 입력된 시퀀스로부터 다른 도메인의 시퀀스를 출력하는 모델이다. 챗봇, 번역기, Speech to Text, 텍스트 요약 등에 사용된다. 모델은 크게 아래와 같이 구성이 된다.

Sequence-to-Sequence 모델 내부를 살펴보면 Encoder와 Decoder로 구성된다. Encoder에서는 입력받은 정보를 하나의 벡터로 만드는데 이를 Context Vector라고 한다. Context Vector는 입력 데이터의 압축된 정보라고 할 수 있다.

일반적으로 Seq2Seq 모델에서 Encoder와 Decoder의 내부는 RNN, LSTM, GRU 등의 셀들로 구성된다.
번역기로 예를 들면 아래 그림과 같다.
RNN 기반 모델들은 자기 회귀(Autoregressive) 특성을 갖기 때문에 “나는” → “학생” → “입니다”가 순차적으로 입력된다.

Inference 과정에서 Encoder의 추론이 끝난 후에 Decoder에 <sos> 토큰과 Context Vector가 주어지며, 이를 바탕으로 다음 단어를 예측하며 예측한 단어는 다음 RNN 셀에 입력된다.
Train 과정에서 Decoder는 Encoder가 보낸 Context Vector와 `<sos> I am a student`라는 입력이 들어오면, `I am a student <eos>` 가 출력되도록 학습되는데 이를 teacher forcing(교사 강요)라고 한다.
컴퓨터는 일반적으로 텍스트보다 숫자를 더 잘 처리하기 때문에, 텍스트를 Vector로 바꾸기 위해 Word Embedding이 사용된다.

Decoder에서 RNN 셀의 출력마다 Fully Connected Layer와 Softmax를 거친 후에 각 단어가 나올 확률을 예측하게 되며 아래 그림이 seq2seq 모델의 전체 구조이다.

Attention Mechanism
RNN 기반의 seq2seq 모델에는 크게 두 가지 문제가 있다.
- 첫째, 하나의 고정된 크기의 벡터(Context Vector)에 모든 정보를 압축하려고 하기 때문에 정보 손실이 발생한다는 점
- 둘째, RNN의 고질적인 문제인 기울기 소실 문제
이러한 문제를 해결하기 위해 제시된 것이 Attention이다. Seq2Seq에서 Attention은 Decoder에서 출력할 때, Encoder의 어떤 정보에 집중해야 되는지 도움을 주는 역할을 함.

즉, Attention은 Decoder에서 출력 단어를 예측할 때 매 시점(time step)마다, Encoder에서 전체 입력 문장을 다시 한번 참고한다는 점이다. 해당 시점에서 예측해야 할 단어와 연관이 있는 입력 단어를 좀 더 Attention 하게 되는 것이다.
Attention 과정을 살펴보면 다음과 같다.
- Decoder의 Hidden State와 Encoder의 Hidden States와 유사도를 구한다. (Attention Score)
- 구해진 유사도에 Softmax 연산을 한 후 다시 Encoder의 Hidden states를 곱하고 합한다. (Attention Value)
- Decoder의 Hidden State에 Attention Value를 Concat 후 FC Layer와 Softmax를 거쳐 결과 출력한다.

앞으로 Attention에서 계속 나오는 키워드가 있는데 그것은 Query, Key, Value에 대한 부분이다.
아래 그림에서 Decoder의 Hidden State가 Query, Encoder의 Hidden States가 Key, Value가 된다.

Transformer에서 Attention에 관한 내용은 밑에서 자세히 다룬다.
🤖 Transformer
대부분의 시퀀스 변환 모델은 Encoder-Decoder 구조를 가지고 있으며 AutoRegressive 성격을 갖고 있다. 하지만, Transformer는 토큰을 순차적으로 입력받지 않고 한꺼번에 입력(학습 시) 받으며 RNN 기반 셀 없이 Attention 만을 사용하였다.
모델 구조는 아래와 같으며 왼쪽은 Encoder, 오른쪽은 Decoder라고 볼 수 있다.
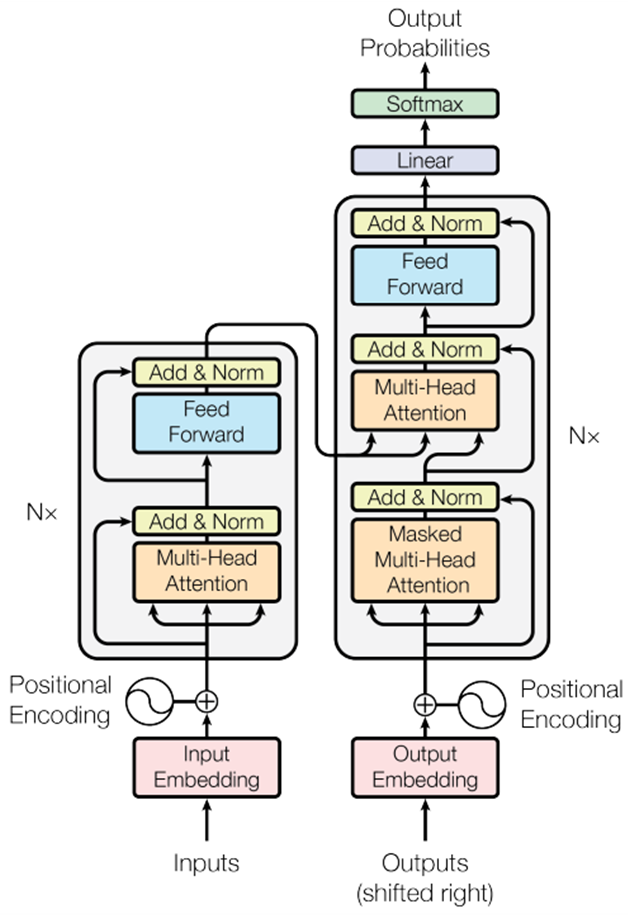
Encoder
Encoder는 N=6으로 동일한 Layer의 스택으로 있으며 Sub-Layer에는 Multi-head Attention과 Feed Forward로 구성되어 있다. 이후에는 각각 Residual Connection과 Layer Normalization을 사용했다. Residual Connection을 쉽게 하기 위해 Sub-Layer와 Embedding Layer는 $d_{model}=512$의 출력을 생성하게 했다.

Decoder
Decoder도 N=6으로 동일한 Layer 스택으로 되어 있으며 Sub-Layer에는 Masked Multi-Head Attention, Multi-Head Attention, Feed Forward로 구성되어 있다. 이후에 Encoder와 동일한 형식으로 Residual Connection과 Layer Normalization을 사용했다.

Attention
Attention은 Query와 Key의 유사도를 계산하여 해당 유사도를 가중치로 사용해 Value를 결함함으로써 Attention Value를 얻는 방법이다. Attention은 Additive attention과 Dot-product attention이 주로 쓰이지만 해당 논문에서는 Scaled Dot-Product Attention을 사용한다.


Scaled Dot-Product Attention은 Dot-product에 \frac1{d_{k}}를 곱해주는 부분이 추가된 것이다. 기존 Dot-product Attention은 d_{k}값이 커지면 Additive Attention보다 성능이 떨어졌는데 이를 완화시키기 위해 Scale 하는 부분을 추가했다.
$d_{k}$값이 커지면 성능이 떨어지는 이유
$Q, K$ 값은 평균이 0, 분산이 1인 랜덤 값이지만, $d_k$의 값에 따라 $Q$와 $K$를 내적 했을 때 평균은 0, 분산은 $d_k$가 된다. Softmax 함수의 입력 값들이 지나치게 커지게 되어, 확률 분포가 한쪽으로 치우치는 현상이 발생할 수 있어 Scale을 하여 학습 과정을 더 안정적으로 진행되게 한다.

Multi-Head Attention 구조를 보면 Scale Dot-Product Attention이 Head의 개수만큼 병렬적으로 구성되어 있다. 이러한 구조를 통해 각 Head는 서로 다른 관점에서 입력 데이터의 특징을 학습할 수 있게 된다.

$Q, K, V$를 각각의 Fully-connected Layer인 $W_q, W_k, W_v$를 통과시킨 후 Head 수만큼 Split 시킨다. 이후에 Split 된 $Q'_i, K'_i, V'i$가 각각 Multi-Head Attention 이후 Concat 된다.
- $d_k=\frac{d_{model}}h$

Transformer에서는 multi-head attention을 3가지 방식으로 사용한다.
- 1번에서 Query는 Decoder에서 나오고 Key와 Value는 Encoder의 출력에서 나온다. 이를 통해 Decoder의 모든 위치에서 Input Sequence의 모든 위치에 Attention을 할 수 있다.
- 2번에는 Encoder에 Input Sequence에서 Self-Attention을 수행함으로써 각 토큰은 자신뿐만 아니라 다른 토큰과의 관계를 학습할 수 있다.
- 3번에서는 Masking을 사용해 모델이 각 시점에서 이전까지 생성된 정보 만을 사용 하여 다음 단어를 예측하도록 했다.

Masked Multi-Head Attention은 주로 학습 단계에서 사용된다.
예를 들면, 학습 시에 Decoder는 “<sos> I am a student”를 입력받아 “I am a student <eos>”를 생성하도록 학습한다. 이때 masking을 통해 현재 위치의 단어를 예측할 때 미래 시점의 단어들은 참조할 수 없도록 한다. 즉, Masking은 모델이 각 시점에서 이전까지 생성된 정보만을 사용하여 다음 단어를 예측하도록 강제하는 메커니즘이다.

Position-wise Feed-Forward Networks
Transformer의 Sub Layer에서 Feed Forward 부분을 설명할 때 본 논문에서는 Positional-wise Feed-Forward Networks라고 설명한다. Position-wise가 붙는 이유는 각 토큰에 독립적으로 적용되기 때문이다.

Embeddings and Softmax
- Transformer에서도 다른 시퀀스 변환 모델처럼 Embedding을 사용해 입력 및 출력 토큰을 벡터로 변환한다.
- Transformer에서는 Embedding Layer와 Pre-Softmax Linear Transformation에서 동일한 가중치 행렬(W=E^T)을 공유한다.
- Embedding에서는 이 가중치를 모델 차원(d_model)의 제곱근으로 스케일링하여 사용한다.
- 이는 파라미터 수를 줄이고, 학습을 더 효율적이고 안정적으로 하기 위해 사용된다.

Positional Encoding
Transformer는 순차적으로 입력을 처리하지 않기 때문에 순서 정보를 positional Encoding으로 제공한다. Positional Encoding에는 여러 방법이 있지만 Transformer에서는 서로 다른 frequencies의 사인 함수와 코사인 함수를 사용한다.
(Positional Encoding에 대한 내용은 나중에 더 자세히 다루겠습니다.)


🧪 실험 및 결과
- 데이터는 WMT 2014 영어-독일어 데이터셋 (450만 문장 쌍)과 WMT 2014 영어-프랑스어 데이터셋 (3600만 문장 쌍)을 사용
- 영어-독일어 데이터셋은 바이트-쌍 인코딩(BPE)을 사용하여 약 37,000개의 공유 어휘를 생성했고, 영어-프랑스어 데이터셋은 32,000개의 WordPiece 어휘를 사용
- 문장들은 길이를 기준으로 배치되었으며, 각 배치는 약 25,000개의 소스 토큰과 25,000개의 타겟 토큰을 포함
- 학습은 8개의 NVIDIA P100 GPU가 장착된 한 대의 머신에서 진행
이 외 학습 관련 파라미터는 다루지 않겠습니다. (논문 참고)
- 기계 번역의 품질을 평가하는 대표적인 지표인 BLEU 스코어를 기준으로 살펴보면, Transformer 모델이 기존의 다른 모델들과 비교하여 우수한 성능을 보여줌.
- BLEU 스코어는 기계 번역 결과물이 인간 번역가의 결과물과 얼마나 유사한지를 수치화한 평가 지표
- Transformer가 높은 번역 성능을 달성하면서도 학습에 필요한 컴퓨팅 자원(training cost)을 효율적으로 사용

- Attention의 Head의 수가 중요한 것을 볼 수 있으며, 단일 Head는 최적 설정보다 0.9 BLEU 낮은 성능을 보였으며, 너무 많은 Head도 성능 저하를 가져옴.
- Attention Key의 크기($d_k$)를 줄이면 모델 성능이 저하되며 이는 dot product보다 더 정교한 호환성 함수가 필요할 수 있음을 보여줌
- 모델 크기가 클수록 성능이 향상되었으며 Dropout이 Overfitting 방지에 효과적
- Sinusoidal positional encoding을 학습된 positional embedding으로 대체했을 때 기본 모델과 거의 동일한 결과를 보임

- Transformer가 다른 Task(English constituency parsing)에서 일반화를 잘할 수 있는지 평가
- English constituency parsing : 영어 구 구문 분석
- 특별한 Tuning 없이도 우수한 성능을 보였음
- RNN기반 seq2seq 모델은 소규모 데이터셋에서 성능이 좋지 못하지만, Transformer는 비교적 작은 데이터셋에서도 뛰어난 일반화 성능을 보이며 기존 RNN의 한계를 극복. (데이터가 매우 작을 때는 일반화를 잘 못할 수도 있음)
(++ 논문에서 말하는 소규모 데이터의 크기는 40k이다. 이는 transformer를 학습시키기에 충분한 크기이며 매우 작은 데이터셋이라고 생각하면 안 될 것 같다.)

🏁 결론
본 논문은 Encoder-Decoder 구조에서 가장 많이 사용되던 Recurrent Layer를 Multi-head Self-attention으로 대체한 Transformer 구조를 제안하였으며 번역 Task에서 RNN 기반, CNN 기반 모델보다 훨씬 더 빠르게 학습이 가능했으며 성능도 우수했다.
📄 참고자료
https://wikidocs.net/book/2788
'AI Research' 카테고리의 다른 글
| [Paper Review] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2025.01.24 |
|---|---|
| [Code] VAE(Variational Auto-Encoder) 구현 (0) | 2024.03.28 |
| [Stable Diffusion] 상황 별 Negative prompt (1) | 2024.01.09 |
| Diffusion Model vs GANs (2) | 2023.12.28 |