
[Paper Review] Learning Transferable Visual Models From Natural Language Supervision
Paper : https://arxiv.org/pdf/2103.00020
Github : https://github.com/OpenAI/CLIP
CLIP은 OpenAI에서 개발한 모델로, 기존 컴퓨터 비전 시스템의 한계를 극복하기 위해, 고정된 객체 카테고리 대신 원시 텍스트로부터 직접 학습하는 접근법을 제시했다. 4억 개의 (이미지, 텍스트) 쌍으로 구성된 인터넷 데이터셋을 사용해 이미지-텍스트 매칭을 통해 사전 훈련하며 자연어를 통해 학습된 시각적 개념을 참조하고 Zero-shot Transfer가 가능하게 한다. 30개 이상의 다양한 비전 데이터셋에서 성능 벤치마크를 수행했으며 뛰어난 성능을 보였다.
CLIP 모델 자체는 매우 간결한 구조를 가지고 있지만, 논문(48페이지로 일반적인 논문보다 2~3배 분량)에서는 많은 실험과 분석이 포함되어 있어 여러 Insight를 얻을 수 있다. CLIP의 기본 개념만 파악하고 싶다면, 실험 결과 부분 이전까지만 읽어도 충분할 것 같다.

📚 사전 지식
이 논문을 효과적으로 이해하는 데 필요한 사전 지식을 정리했다.
Task-agnostic
Task agnositc이란 특정 작업(task)에 국한되지 않고 다양한 작업에 두루 적용될 수 있는 특성을 의미한다. Task agnostic한 AI 모델 중 하나는 GPT와 같은 LLM 모델이다. 이는 번역, 요약, 코딩, 작문 등 다양한 작업을 하나의 모델로 수행할 수 있다. 이와 같이 특정 작업에 특화되지 않고 범용적으로 활용 가능하다는 특징이 있다. Task agnostic의 장점은 모델이나 방법론의 재사용성이 높고 새로운 작업에 빠르게 적용할 수 있다는 것이다. 반면 특정 작업에 최적화된 task-specific 접근법에 비해 성능이 다소 떨어질 수 있다는 단점도 있다.
Zero-Shot Learning
일반적인 머신러닝 모델은 특정 대상을 인식하기 위해 해당하는 모든 데이터를 학습해야 한다. 하지만 Zero-shot Learning은 이런 제약에서 벗어나 한 번도 학습하지 않은 객체나 개념도 인식할 수 있는 방식이다.
예를 들어, 모델이 수달, 오랑우탄, 사자만을 학습했더라도 고양이나 물개와 같은 새로운 동물을 인식할 수 있다. 즉, Zero-shot Learning은 모델이 학습하지 않은 새로운 Task도 잘 수행하도록 하는 기술이다.
Bag-of-words
Bag-of-words란 단어들의 순서는 고려하지 않고, 단어들의 출현 빈도(frequency)에만 집중하는 텍스트의 수치화 표현 방법이다. 아래 이미지처럼 각 단어는 고유한 인덱스를 가진 벡터로 변환되며, 해당 단어의 출현 횟수가 벡터의 값이 된다.
Gold Label
골드라벨이란 전문가나 숙련된 annotator에 의해 수작업으로 레이블링된 데이터다. 일반적으로 높은 품질과 신뢰도를 갖고 있다. 다만 시간과 비용이 많이 들기 때문에, 실제로는 제한된 양의 골드 라벨 데이터만 사용할 수 있는 경우가 많다.
🖇️ CLIP
CLIP 모델 구조는 아래와 같다.
왼쪽은 학습 과정, 오른쪽은 추론 과정이라고 생각하면 된다.
학습 시에는 Batch 내의 모든 텍스트-이미지 쌍에 대해 유사도를 계산한다. 같은 Pair의 텍스트-이미지 쌍의 유사도는 높이고, 다른 Pair의 텍스트 이미지 쌍의 유사도는 낮추는 방향으로 학습하게 된다.
추론 시에는 먼저 Class Label 을 Text Encoder에 입력시켜 Text Vector들을 미리 계산하고, 입력 이미지를 Image Encoder에 통과시켜 Image Vector를 얻는다. Image Vector와 모든 Text Vector들 간의 유사도를 계산하여 가장 높은 유사도를 가진 Label을 예측 Class로 선택한다.
단순히 CLIP이 어떻게 동작하는지 이해하려면 이게 끝이지만 어떤 과정이 있었는지 조금 더 자세히 살펴본다.
Natural Language Supervision
CLIP의 핵심은 자연어에 포함된 Supervision을 통해 인식(perception)을 학습하는 것이다. 여러 연구에서 이미 이미지와 텍스트를 결합한 학습 방법을 제시했지만 각각 다른 학습 방식을 사용했다.(Unsupervised, Self-supervised 등등) 자연어를 학습 Signal로 사용한다는 점은 공통적이다.
초기 연구에서는, 토픽 모델과 n-gram 모델에서 자연어의 복잡성을 다루는데 어려움이 있었으나, 자연어처리 분야의 발전으로 효과적으로 활용할 수 있게 됐다. (심층 문맥 표현 학습의 개선)
Natural Language Supervision의 장점은 기존의 이미지 분류를 위한 라벨링에 대해서 확장이 쉽고 인터넷의 방대한 텍스트 데이터를 활용할 수 있다는 점이다. 이를 통해 단순한 표현을 학습하는게 아니라 언어와의 연결을 통해 유연한 Zero-shot Transfer가 가능하다.
Creating a Sufficiently Large Dataset
데이터셋을 구성할 때 이전의 연구들은 주로 MS-COCO, Visual Genome, YFCC100M을 사용했으나 각각의 한계가 있었다.
- MS-COCO와 Visual Genome: 고품질의 크라우드 라벨링 데이터셋이지만 각각 약 10만 장으로 규모가 작음
- YFCC100M: 1억 장의 큰 규모지만 메타데이터 품질이 낮고, 영어로 된 자연어 설명만 필터링하면 1,500만 장으로 크게 감소
이러한 한계를 극복하기 위해 CLIP은 더 큰 규모의 총 4억 쌍의 이미지-텍스트로 이루어진 WIT(WebImageText) 데이터셋을 구축했다. 주요 특징은 다음과 같다.
- 50만 개의 쿼리 세트를 활용해 다양한 시각적 개념을 포괄
- 쿼리당 최대 2만 개의 (이미지, 텍스트) 쌍을 포함하여 클래스 밸런스 조정
- 총 단어 수는 GPT-2 훈련 데이터셋과 유사한 규모

Selecting an Efficient Pre-Training Method
CLIP은 효율적인 사전 학습 방법을 선택하기 위해 여러 접근법을 시도했다. 초기에는 VirTex처럼 이미지 CNN과 텍스트 트랜스포머를 처음부터 함께 학습시켜 이미지의 캡션을 예측하는 방식을 사용했으나 여러 어려움이 있었다.
본 논문에서는 다음과 같은 발견을 했다.
- 텍스트의 정확한 단어를 예측하는 것은 이미지와 함께 나타나는 다양한 설명과 코멘트로 인해 어려운 작업이었다.
- Contrastive Learning으로 학습하는 것이 일반적으로 Prediction 하는 것보다 더 나은 표현(representation)을 학습할 수 있음을 발견했다.
- 정확한 단어 예측 대신, 어떤 텍스트가 어떤 이미지와 쌍을 이루는지만 예측하는 더 쉬운 작업으로 전환했다.

앞에서 간단히 설명했지만, CLIP은 Image Encoder와 Text Encoder를 동시에 학습시키게 된다. 이때 같은 Pair의 Cosine similarity는 최대화하고, 다른 쌍의 Cosine Similarity는 최소화한다. 이때 유사도에 대해서 Symmetric Cross Entropy Loss를 통해 최적화한다. pseudocode를 보면 아래와 같다.

학습 과정에서 주목할만한 특징은 다음과 같다:
- 대규모 사전 학습 데이터셋으로 인해 과적합이 큰 문제가 되지 않았다.
- Image Encoder와 Text Encoder 모두 처음부터 학습했다.(사전 학습된 가중치 사용하지 않음)
- 각 데이터를 Embedding 시킬 때 Non-linear projection 대신 Linear projection을 사용했다.
- Data Augmentation은 Resize 된 이미지에서 무작위 정사각형 Crop만 사용했다.
- temperature 파라미터 τ는 Softmax에서 Log의 범위를 제어하는 역할을 하며 학습 중에 최적화가 된다.
Choosing and Scaling a Model
Image Encoder에는 ResNet 또는 ViT, Text Encoder에서는 Transformer를 사용했다.
ResNet에서는 Global Average Pooling 대신 Attention pooling을 사용하였으며 ViT에서는 Patch와 position Embedding에서 Additional Layer Normalization을 적용했다.
이외에도 ResNet, ViT, Tranformer 모델을 사용할 때 일부 수정을 하여 사용했다.
이미지와 텍스트를 효과적으로 Embedding 하기 위해 최신 기술들을 통합하고, 균형 있게 스케일링하였다.
Training
ResNet 계열 5개(ResNet-50, ResNet-101, RN50x4, RN50x16, RN50x64)와 ViT 계열 3개(ViT-B/32, ViT-B/16, ViT-L/14)를 학습하였다.
32 Epoch 동안 학습 하였으며 Adam Optimizer를 사용했다. Mini-Batch 크기는 32,768로 학습을 진행했다.
(이 외에 자세한 사항들은 논문을 참고해 주세요.)
RN50x64 는 592개의 V100 GPU로 18일이 소요됐으며, ViT-L/14는 256개의 V100 GPU로 12일이 소요됐다.
아래 Figure를 볼 때, 특별히 명시되지 않으면 ViT-L/14@336px 모델을 사용한 것이다.
🧪 실험 및 결과
Zero-Shot Transfer
일반적인 컴퓨터 비전에서 Zero-shot Learning은 보지 않은 객체 카테고리에 대한 일반화를 의미하지만 CLIP은 이를 확장해서 보지 않은 데이터셋에 대한 일반화로 사용했다.
CLIP은 Zero-Shot Transfer를 통해 Task-Learning 능력을 측정하고자 하며 NLP에서의 진전을 컴퓨터 비전에 적용하여 모델이 특정 Task에 명시적으로 훈련되지 않았더라도 새로운 시각적 Task를 수행할 수 있는 방식으로 Zero-shot Learning을 활용한다.
아래 표와 같이 Visual N-Grams 모델(초기 Zero-shot Transfer)과 비교했을 때 우수한 성능을 보인다.
하지만, CLIP은 10배 더 큰 데이터셋으로 학습하고 더 많은 컴퓨팅 리소스를 필요로 한다. 또한, Visual N-Grams이 나왔을 때는 존재하지 않았던 Transformer 기반 모델을 사용했다.

아래 이미지는 Prompt Engineering의 중요성을 보여준다. 일반적인 데이터셋에서 숫자 ID와 영어 이름 매핑하는데 일부 데이터셋(Flowers102, GTSRB)은 이러한 매핑을 하고 있지 않아 Zero-shot Transfer가 불가능하다. 이 외에도 클래스 이름만으로는 문맥에 대한 정보를 알 수가 없어 정확한 의미 구분이 어렵고 CLIP은 사전 훈련 데이터셋에서 단일 단어보다 전체 문장이 더 일반적이다.
이러한 문제점들을 개선하기 위해 “A photo of a {label}”과 같은 식으로 기본 Prompt Template을 사용했다.
세부 이미지 분류에서는 카테고리를 명시해 줬으며(”a type of pet”, “a type of food”), OCR 데이터셋은 텍스트나 숫자를 따옴표로 묶어줬다. 위성 이미지의 경우 “A satellite photo of a {label}” 형식을 사용했다.
다양한 Context Prompt를 사용해 여러 Zero-shot Classifier를 생성하였으며 ImageNet에서 80개의 다른 Context Prompt Ensemble로 3.5% 추가 성능 향상을 했다.
- 예를 들어, “A photo of a big {label}”, “A photo of a small {label}” 등 총 80가지 다른 표현을 사용하고 각각 예측한 결과를 모아서 최종 결과를 내는 형식
이렇게 Prompt Engineering과 Ensemble 기법을 함께 사용하면 ImageNet에서 정확도가 약 5% 향상했다.

아래 그림을 보면 27개의 데이터 셋에 대한 비교를 보여준다. Zero-shot CLIP은 27개의 데이터셋 중 16개에서 기준보다 더 나은 성능을 보여줬다. Zero-shot CLIP이 성능이 떨어지는 부분을 보면, 위성 이미지 분류(EuroSAT 및 RESISC45), 림프절 종양 감지(PathCamelyon), 합성 장면에서 객체 수 계산(CLEVRCounts), 독일 교통 표지판 인식(GTSRB), 가장 가까운 차량과의 거리 인식(KITTI Distance) 등 여러 전문적이고 복잡하거나 추상적인 작업에는 Zero-shot CLIP이 취약하다는 것을 알 수 있다. 하지만 이러한 데이터셋은 전문가가 아닌 사람도 어려워하는 작업들이다.

아래 그림은 Zero-shot과 Few-shot 방법을 비교한 내용이다. Zero-shot CLIP은 자연어를 통해 시각적 개념을 직접 명시할 수 있기 때문에 Zero-shot 임에도 성능이 높다. BiT-M(ImageNet-21K)에서 16-shot과 비슷한 성능을 보인다.

아래 그림은 Zero-shot CLIP과 같은 Feature Space에서 훈련된 Logistic Regreesion Classifier에서 학습 데이터 효율성을 평가한 것이다. 데이터셋의 절반은 Class당 5개 미만의 example이 필요하며, 중앙값은 5.4개 평균적으로는 20.8개의 example이 필요하다. Flowers102와 EuroSAT 두 데이터셋에서는 Zero-shot이 1-shot 모델보다 성능이 낮았으며 ImageNet에서 Zero-shot CLIP은 16-shot Linear Classifier와 동등한 성능을 보였다.

아래 그림의 x축은 Linear Probe CLIP의 성능, y축은 Zero-shot CLIP의 성능을 보여준다. Zero-shot Clip이 성능이 10~25% 낮은 것을 볼 수 있으며 Zero-shot Transfer에서 개선할 여지가 많다는 것을 의미한다. STL10, CIFAR10, Food101, OxfordPets, Caltech101 데이터셋에서는 지도학습 성능에 근접한 것을 볼 수 있다.
해당 데이터셋들에서는 두 성능 모두 90% 이상을 기록했다. 이는 기본 표현 품질이 높은 태스크에서 Zero-Shot Transfer가 더 효과적일 수 있음을 보여준다.
[아래 그림에서 파란색 선은 Linear Probe CLIP Performance와 Zero-Shot CLIP Performance 사이의 상관관계를 나타내는 회귀선 (regression line)]

지난 몇 년간의 딥러닝 시스템에서는 컴퓨팅 자원을 키움에 따라 Zero-shot 성능이 일관되게 향상되는 것을 보여줬다. CLIP 모델도 유사한 패턴을 따르는지 확인을 해본 결과 아래와 같이 성능이 향상되는 것을 볼 수 있다.

Representation Learning
CLIP 모델의 Representation Learning에 대한 능력을 분석한 부분이다. 이를 평가할 때 Finetuning 보다는 Linear probe 방식을 사용했다. (일반적이고 강건한 표현을 명확히 평가할 수 있고 1,782개의 평가를 할 때 더 효율적)
작은 CLIP 모델(ResNet-50, Resnet-101)은 ImageNet-1K로 훈련된 ResNet보다 우수하지만, ImageNet-21K로 훈련된 모델(BiT-M) 보다는 성능이 낮다. CLIP-ViT는 CLIP-ResNet 보다 약 3배 더 계산 효율적이다.

CLIP은 27개 중 21개 데이터셋에서 Noisy Student EfficientNet-L2를 능가한다. 특히, OCR 데이터셋(SST2, HatefulMemes), 지리적 위치 파악(Country211, SUN397), 동영상 행동 인식(Kinetics700, UCF101)에서 큰 향상을 보인다. ImageNet, CIFAR10/100과 같은 저해상도 데이터셋에서는 여전히 Efficient 모델이 더 우수하다.

Robustness to Natural Distribution Shift
CLIP의 견고성(robustness)에 관한 연구를 다루고 있는 부분이다. 2015년에 딥러닝 모델이 ImageNet 테스트에서 인간 성능을 넘어섰지만, 후속 연구들은 이러한 모델들이 여전히 많은 간단한 실수를 한다는 것을 발견했다. 이 불일치의 원인으로는 모델이 훈련 데이터셋에서 유효한 상관관계를 찾지만, 이러한 패턴이 다른 데이터 분포에서는 유효하지 않을 수 있다는 점이 제시되었다.
CLIP의 Zero-shot 모델은 기존 ImageNet 모델보다 견고성이 크게 향상되었으며, Natural Distribution Shift 데이터셋에서 성능이 더 높은 것을 볼 수 있다.

CLIP을 ImageNet 분포에 적응시킨 후, ImageNet 정확도는 9.2% 증가했지만 데이터 분포가 변했을 때 평균 정확도는 약간 감소했다. 특히, ImageNetV2에서만 성능이 크게 향상되었고, 다른 데이터셋에서는 성능이 감소했습니다.

아래 그림에서 볼 수 있듯이, 일부 Sample로 Finetuning 했을 때, Shot 수가 증가할수록 성능이 개선되며, 데이터 분포 변화에도 강해진다. 하지만 0-shot 성능이 가장 높은 걸로 보아 일반화 성능은 오히려 떨어지는 것을 볼 수 있다. (Natural Distribution Shift Dataset 기준)

👤 인간 vs CLIP 성능 비교
아래 표는 5명의 사람에게 Oxford IIT Pets 데이터셋의 3,669개의 이미지를 각각 보고 37개의 고양이 또는 강아지 품종 중 가장 일치하는 것을 선택하게 해 본 결과다.

아래 그림을 통해 CLIP의 가장 어려운 문제도 사람에게 어렵다는 것을 알 수 있다.
오류가 일관된다면 데이터셋의 노이즈(라벨이 잘못 지정된 이미지 포함)와 데이터셋 분포에서 벗어난 이미지가 사람과 모델에게 모두 어렵다는 가설을 세울 수 있다.

📊 데이터 중복 분석
사전 학습 데이터셋에 평가 데이터셋의 일부가 포함되면 일반화 능력 테스트로써의 평가가 의미가 없을 수 있다. 따라서 본 논문에서는 중복을 미리 제거하는 대신, 발생한 중복의 정도와 이로 인한 성능 변화를 문서화했다. 35개 데이터셋 중 9개는 중복이 전혀 없었으며 대부분 중복으로 인한 정확도 변화는 0.1% 미만이었다.
BirdSnap의 경우 12.1%의 중복을 보였고, 이로 인해 0.6%의 성능 향상이 있었다. 가장 큰 중복률은 Country211에서 21.5%였지만, 정확도 향상은 0.2%였다.
이는 대규모 사전 훈련에서 데이터 중복이 성능에 미치는 영향이 생각보다 작다는 것을 보여준다.

⛔ CLIP의 한계
CLIP에는 많은 Limitations들이 존재한다.
- Zero-shot 성능의 한계
- CLIP의 Zero-shot 성능은 RenNet-50 기반의 Linear Classifier 수준이지만, 최신 SOTA 모델에는 미치지 못하며 SOTA 수준으로 올리려면 1000배 이상의 연산량이 필요하다.
- 특정 Task에서 취약점
- 세부적인 분류 모델에서 성능이 낮으며 이미지 속 객체 개수 세기 등의 작업에서 성능이 떨어진다. 또한, 학습 데이터에 없는 개념에서 성능은 무작위 수준이다.
- 일반화 문제
- OOD(Out-of-Distribution) 데이터에 취약하며, 디지털 글자는 잘 인식하는 반면에, 손글씨 데이터셋에서는 낮은 정확도(88%)를 보인다.
- 제한적인 예측 방식
- Zero-shot 분류 시 미리 정의된 클래스 내에서만 선택이 가능하여, 이미지 캡션 생성처럼 새로운 개념을 생성하지 못한다. 이는 CLIP의 효율성을 유지하면서 생성 모델과 결합하는 방법이 연구될 필요가 있다.
- 비효율적인 데이터 활용
- 막대한 데이터 양으로 성능을 보완하지만, 데이터 효율성 자체는 개선되지 않았기 때문에 Self-supervised Learning 및 Self-training 기법과 결합하여 개선해 나가야 한다.
- 검증 방식의 문제
- Zero-shot 모델이지만, 대량의 검증 데이터 사용으로 실제 Zero-shot 환경과 다르며 평가 데이터셋이 다소 편향적으로 선정되었을 수도 있다.
- 사회적 편향 문제
- 인터넷에서 수집한 비정제 이미지-텍스트 쌍을 학습하여, 사회적 편향을 내재할 가능성이 높다.
- Few-shot 성능 저하 문제
- 일부 복잡한 시각 개념들은 텍스트만으로 설명하기 어려우며 Few-shot 학습에서 성능이 기대보다 낮다. 또한, Zero-shot에서 Few-shot으로 넘어갈 때 CLIP 성능이 떨어지는 경우가 있다.
💥 Broader Impacts
CLIP은 임의의 이미지 분류 작업 수행 가능하다. 예를 들어 고양이와 개를 분류하거나, 백화점 내 도둑 탐지 등의 사회적으로 민감한 작업 수행 가능하다. 하지만 AI의 적합성을 평가하고, broader impact 분석이 필요하다.
기존 AI 모델과 달리, 재훈련 없이 사용자 정의 분류기(‘roll your own classifier’) 생성 가능하며 이는 GPT-3 같은 대규모 생성 모델과 유사한 문제를 야기할 수 있으며, 테스트를 통해 예상치 못한 능력이 발견될 수 있다.
CLIP은 텍스트-이미지 검색 및 이미지를 활용한 텍스트 검색에서 높은 성능을 보이며 적은 데이터로 새로운 애플리케이션 적용 가능, 향후 예상치 못한 활용 사례의 등장이 가능하다.
모델의 내재된 편향 분석 필요하며 ****초기 편향 테스트 진행했으나, 범위가 제한적이다. CLIP과 같은 범용 비전 모델의 편향 분석 및 보완책 마련 필요하다. AI 개발자가 보다 폭넓고 맥락적인 편향 테스트 방법을 개발해야 한다.
CLIP은 강력한 분류 및 검색 능력을 갖지만, 사회적 편향과 윤리적 문제를 신중히 평가해야 한다. 특히, 사용자가 임의로 분류기를 만들 수 있는 점은 예상치 못한 활용 및 문제를 초래할 수 있으므로, 철저한 테스트와 지속적인 연구가 필요하다.
Bias
CLIP 모델의 편향(Bias) 문제에 대한 분석이며, Class Design과 알고리즘적 결정이 편향을 어떻게 증폭할 수 있는지 보여준다.

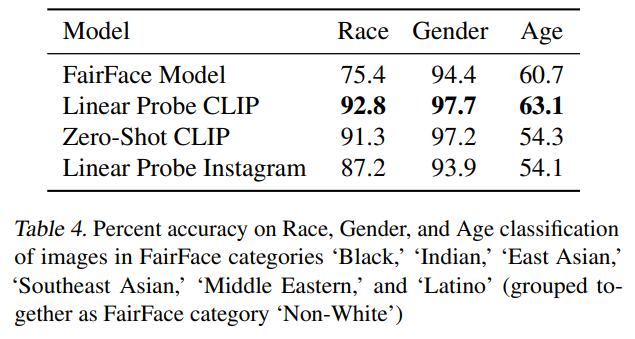
Zero-shot CLIP 모델과 Linear Probe CLIP 모델을 FairFace 데이터셋에 적용하여 Bias를 측정했다. Linear Probe CLIP이 FairFace 모델보다 높은 정확도를 보였지만, 정확도만으로 AI의 공정성을 판단할 수는 없다.

Zero-shot CLIP의 분류 성능은 인종과 성별에 따라 다르게 나타나며, 흑인(Black) 얼굴이 비인간(Animal) 관련 분류로 잘못되는 비율이 14%로 가장 높았다. 또한, 남성이 범죄 관련 클래스로 잘못되는 비율이 여성보다 높았다.

어린이 얼굴이 범죄 및 동물 관련 클래스로 잘못 분류되는 확률이 가장 높았으나 ‘child’ 클래스를 추가했을 때 이러한 Bias가 감소한 것을 볼 수 있다. 이를 통해 Class Design이 Bias 완화에 중요한 것을 알 수 있다.

미국 국회의원(Members of Congress) 사진을 사용한 테스트에서 CLIP 모델은 100% 성별 분류 정확도를 보였다. 하지만 남성과 여성에게 할당된 직업 관련 Label이 달랐다. 낮은 확률 0.5% threshold에서는 여성에게 ‘nanny(보모)’, housekeeper(가정부)’ 같은 Label이 붙었고, 남성에게는 ‘prisoner(죄수)’, ‘mobster(폭력배)’같은 부정적인 Label이 더 많이 할당됐다. 높은 확률 4% threshold에서는 남성과 여성 모두 ‘lawmaker(입법자)’, ‘legislator(의원)’ 등의 Label이 나타났다.
(사용한 데이터로는 Google Cloud Vision, Amazon Rekognition, Microsoft Azure Computer Vision 세 가지 AI 서비스가 국회의원 사진에 대해 반환한 Label을 모은 것)
아래 이미지는 χ2 검정(Chi-Squared Test)을 통해 성별에 따라 차이가 큰 20개의 Label을 선택한 것이다. 막대 바는 특정 Label이 남성과 여성에게 할당된 비율을 나타낸다.

Surveillance
본 논문에서는 감시(surveillance) 분야에서도 CLIP 모델의 성능을 분석했다. 감시는 사회적으로 민감한 주제이며, 연구 커뮤니티가 이에 대한 잠재적 영향을 예측하고 적절한 규범과 점검 기준을 개발하는 것이 중요하다고 보았다.
CCTV 이미지 분류를 할 때 VIRAT 및 Varadarajan & Odobez 데이터셋을 활용해 CLIP의 성능을 테스트했다. 이미지의 주요 내용을 분류하는 실험에서 초기 정확도는 91.8%였으나, 유사한 옵션이 포함된 Stress Test에서는 51.1%로 감소했다. 작은 객체의 존재 유무를 판단하는 실험에서 성능이 랜덤 수준으로 낮았다.

유명인사 얼굴 인식 (Zero-Shot Identity Detection) 실험에서 CelebA 데이터셋을 활용해 100명의 유명인 중 59.2%의 정확도를 보였으며, 범위를 1,000명으로 확장하자 43.3%로 감소했다. 이는 Google의 유명인 인식 모델보다 성능이 낮지만, 사전 학습 데이터만으로 수행된 점에서 의미가 있다. 앞으로 모델이 발전할수록 더 적은 이미지 데이터로도 인물 식별이 가능해질 가능성이 크다.
CLIP은 zero-shot으로 감시 관련 작업을 수행할 수 있는 장점이 있다. 하지만, 감시 분야에서는 이미 성능이 뛰어난 Detectron2 같은 특화 모델이 존재하므로, CLIP의 경쟁력이 크지는 않다. 다만, CLIP은 맞춤형 감시 애플리케이션 개발의 장벽을 낮출 수 있으며, 특정한 감시 용도로 활용될 가능성이 있다.
🏁 결론
본 논문은 NLP에서 성공한 task-agnostic 웹 규모의 사전 훈련 방식을 컴퓨터 비전 분야로 확장시킬 수 있는지 조사했다. 이 접근법을 채택함으로써 Computer Vision 분야에서도 유사한 점이 나타난다는 것을 발견했으며, 이 연구 방향의 사회적 영향에 대해 논의했다.
CLIP 모델은 훈련 목표를 최적화하기 위해 사전 훈련 과정에서 다양한 작업을 수행하는 방법을 학습한다. 이렇게 학습된 작업 능력은 자연어 프롬프팅을 통해 많은 기존 데이터셋에 제로샷 전이가 가능하게 한다.
충분한 규모에서, 이 접근 방식의 성능은 작업 특화된 지도 학습 모델과 경쟁력 있을 수 있지만, 여전히 많은 개선의 여지가 있다.
📄 참고자료
https://ogre51.medium.com/nlp-explain-bag-of-words-3b9fc4f211e8
'AI Research' 카테고리의 다른 글
| [Paper Review] AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE (0) | 2025.01.24 |
|---|---|
| [Paper Review] Attention Is All You Need (0) | 2025.01.13 |
| [Code] VAE(Variational Auto-Encoder) 구현 (0) | 2024.03.28 |
| [Stable Diffusion] 상황 별 Negative prompt (1) | 2024.01.09 |
| Diffusion Model vs GANs (2) | 2023.12.28 |